Scalable AI Solutions: Building Cloud-Native RAG Systems for Enterprise FinTech

Introduction
Retrieval-Augmented Generation (RAG) is revolutionizing how financial institutions handle data and generate insights. This guide will walk you through building a cloud-native RAG system for enterprise FinTech applications.
TL;DR
Build a cloud-native RAG system for FinTech using OpenAI, Pinecone, and Flask. Process financial docs, generate embeddings, and get AI-powered responses. Get the complete FinTech-RAG-System here.
System Architecture
Before we dive into the step-by-step guide, let’s visualize how our RAG system will work. The following diagram illustrates the flow of data and the interaction between different components of the system:
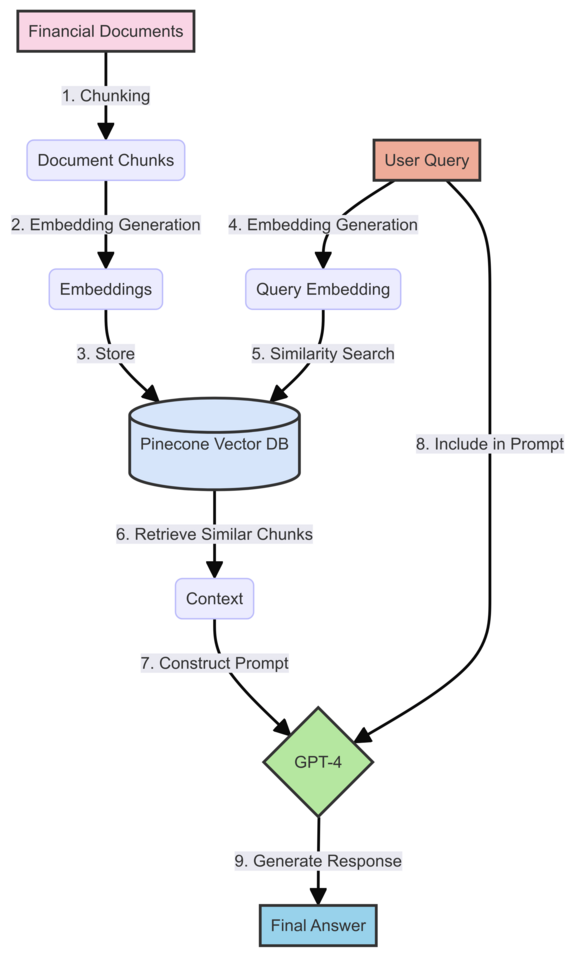
This diagram shows both the document processing flow (steps 1-3) and the query processing flow (steps 4-9), it should will help you understand how each component we’re about to build fits into the larger system.
Current State of Technology
Key Components:
- Large Language Models (LLMs): OpenAI’s GPT-4, Anthropic’s Claude, or open-source alternatives like Llama 2.
- Vector Databases: Pinecone, Weaviate, or Milvus for efficient similarity search.
- Embedding Models: SentenceTransformers, OpenAI’s text-embedding-ada-002, or domain-specific models.
- Cloud Platforms: AWS, Google Cloud, or Azure for scalable infrastructure.
Go-To Tools:
- LLM: OpenAI’s GPT-4 (for its superior performance in financial contexts)
- Vector Database: Pinecone (for its ease of use, scalability, and free tier!)
- Embedding Model: text-embedding-ada-002 (for its performance and compatibility with GPT-4)
- Cloud Platform: AWS (for its comprehensive services and wide adoption in finance)
Building a RAG System: Step-by-Step Guide
Step 1: Data Preparation
- Collect and clean financial documents (reports, news articles, regulatory filings).
- Chunk documents into smaller segments (e.g., paragraphs or sentences).
import nltk
from nltk.tokenize import sent_tokenize
nltk.download('punkt')
def chunk_document(doc, max_chunk_size=1000):
sentences = sent_tokenize(doc)
chunks = []
current_chunk = ""
for sentence in sentences:
if len(current_chunk) + len(sentence) <= max_chunk_size:
current_chunk += sentence + " "
else:
chunks.append(current_chunk.strip())
current_chunk = sentence + " "
if current_chunk:
chunks.append(current_chunk.strip())
return chunks
# Example usage
document = "Your long financial document text here..."
chunks = chunk_document(document)
Step 2: Embedding Generation
Use OpenAI’s API to generate embeddings for each chunk.
import openai
import os
openai.api_key = os.getenv("OPENAI_API_KEY")
def generate_embedding(text):
text = text.replace("\n", " ")
response = client.embeddings.create(input=[text], model="text-embedding-3-small")
return response.data[0].embedding
# Generate embeddings for chunks
chunk_embeddings = [generate_embedding(chunk) for chunk in chunks]
Step 3: Vector Database Setup
Set up Pinecone and insert the embeddings.
from pinecone import Pinecone, ServerlessSpec
# Initialize Pinecone
pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY"))
# Create or connect to the Pinecone index
index_name = "fintech-documents"
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=1536,
metric='cosine',
spec=ServerlessSpec(
cloud='aws',
region='us-east-1'
)
)
index = pc.Index(index_name)
Step 4: Query Processing
Implement the RAG system to process user queries.
def process_query(query):
query_embedding = generate_embedding(query)
search_results = index.query(vector=query_embedding, top_k=3, include_metadata=True)
context = " ".join([result.metadata['text'] for result in search_results.matches])
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a financial expert assistant. Use the following context to answer the user's question."},
{"role": "user", "content": f"Context: {context}\n\nQuestion: {query}"}
]
)
return response.choices[0].message.content
# Example usage
user_query = "What are the recent trends in cryptocurrency regulations?"
answer = process_query(user_query)
print(answer)
Step 5: Cloud Deployment
To containerize your application, create a Dockerfile in your project root:
FROM python:3.9-slim
WORKDIR /app
COPY . /app
RUN pip install --no-cache-dir -r requirements.txt
EXPOSE 8000
# Run app.py when the container launches
CMD ["python", "app.py"]
Make sure to create a requirements.txt file with all the necessary dependencies:
nltk==3.8.1
openai==1.35.14
pinecone==4.0.0
Flask==3.0.3
Scenarios and Use Cases
Regulatory Compliance: Use RAG to quickly retrieve and summarize relevant regulations for specific financial products or services.
Market Analysis: Process large volumes of financial news and reports to generate insights on market trends and potential investment opportunities.
Risk Assessment: Analyze historical data and current market conditions to evaluate potential risks for various financial instruments.
Customer Support: Implement a chatbot that can access a vast knowledge base to answer customer queries about financial products and services.
Conclusion
Building a cloud-native RAG system for enterprise FinTech applications involves combining powerful language models, efficient vector databases, and scalable cloud infrastructure. By following this guide, you can create a system that enables querying vast amounts of financial data and provides accurate, context-aware responses.
Remember to continuously update your document database and fine-tune your models to ensure the system remains current with the latest financial information and regulations.